Mestre em Eng. Eletrônica e Computação
Pelotas–RS, Brasil
Da frustração ao chatbot: como transformamos uma ideia em um estudo de caso de sucesso
Quarta-feira, 20 de junho de 2018. Essa foi a data do primeiro commit realizado no repositório do GitHub de um projeto que eu e o Matheus iniciamos o desenvolvimento em uma noite bastante agradável de inverno. O projeto do qual estou falando se trata de um chatbot, utilizando o mensageiro instantâneo Telegram, que extraia os dados contidos no sistema da universidade onde estudávamos e os apresentava de forma textual para o usuário (aluno vinculado à instituição) sem que fosse necessário o esforço de acessar ao portal inúmeras vezes durante o dia para a conferência das informações. Em outras palavras, nós automatizamos uma tarefa repetitiva em um serviço à parte redirecionando não só o nosso tempo mas também o tempo de diversos usuários do serviço para atividades mais importantes.
O projeto nasceu majoritariamente devido a uma frustração que estávamos enfrentando na época com o sistema da instituição (principalmente em relação a sua usabilidade em dispositivos móveis) e, em uma conversa informal, um questionamento despretensioso resultou na ideia que deu origem a todo o desenvolvimento do chatbot. O resultado desse trabalho nos encheu de orgulho e o processo como um todo nos trouxe bastante alegria e nos ensinou muito, nos mais diversos âmbitos. Consideramos ele como um divisor de águas em nossas carreiras, impactando principalmente na forma como atuamos hoje, seja no relacionamento com outras pessoas ou pela forma como estruturamos nossa lógica para a solução de um problema.
Neste ínterim, o intuito desta publicação é apresentar como transformamos a ideia oriunda de uma frustração conjunta em um estudo de caso que atingiu organicamente cerca de 450 alunos da instituição durante os 11 meses em que o serviço foi ofertado de forma gratuita aos alunos, além de revelar alguns detalhes e curiosidades do seu desenvolvimento, os desafios encontrados durante o percurso e como fizemos para superá-los.
A ideia
Era uma noite de inverno bastante amena e tranquila, fazia cerca de 10 °C. Eu estava passando a semana na casa do Matheus, que fica localizada no município vizinho, para estudar e finalizar alguns trabalhos que ainda estavam pendentes para serem entregues naquele semestre. Cada um de nós estava em sua máquina concentrado em um trabalho diferente. Havíamos jantado não fazia muito tempo, mas em um momento de cansaço mental fizemos uma pausa e fomos rumo à cozinha para fazer um lanche e conversar a respeito de outras coisas, esfriar um pouco a cabeça. Lembro-me claramente de, enquanto conversávamos, checar pelo smartphone o sistema da universidade a cada 5 minutos aguardando a publicação das notas finais das avaliações que havíamos feito nas semanas anteriores àquele dia. Para todo estudante de graduação em final de semestre, aquele era um daqueles momentos definitivos onde, segundo o ditado popular, "ou ia, ou rachava".
O assunto da conversa naquela noite só girava em torno do sistema da universidade, cuja usabilidade nunca foi, diga-se de passagem, lá essas coisas. Haviam diversos problemas estruturais e de navegação que já havíamos identificado em ocasiões anteriores e que eram de fácil correção por um desenvolvedor qualificado. Discorríamos justamente sobre essas mazelas do sistema e como faríamos para corrigi-las. Todavia, a reclamação naquele momento girava em torno do sistema estar bastante lento devido ao número de acessos simultâneos. Era um problema recorrente; todo final de semestre acontecia a mesma coisa. O servidor onde o sistema estava hospedado não dava conta de processar tantas requisições em um curto espaço de tempo e isso acabava prejudicando a experiência de uso tanto dos alunos quanto dos professores.
Após finalizarmos o nosso lanche, voltamos para o quarto ainda conversando em relação ao sistema. O Matheus sentou frente ao seu computador e eu me recostei na parede que fazia divisa com a lareira da sala (e que, para a minha felicidade, reterá todo o calor do fogo que havia sido feito mais cedo e passará para o quarto durante à noite em uma lenta troca de calor), coloquei o tablet no colo, acessei o sistema novamente e comecei a murmurar a respeito de como os problemas de lentidão poderiam ser resolvidos se houvesse alguma API onde pudéssemos consumir os dados, ou então algum aplicativo que os consumisse e utilizasse alguma técnica de armazenamento em cache para que a sobrecarga do sistema fosse menor, especialmente durante esses períodos conturbados de final de semestre.
Naquela época, estávamos bastante interessados em tecnologias emergentes, e os chatbots estavam dentre os assuntos em alta no cenário brasileiro. Embora não fossem a última novidade no mercado, os chatbots estavam engatinhando rumo a uma adaptação para o modelo de consumo no país e tiveram um de seus booms no ano de 2018, segundo o relatório publicado pela Deloitte. Se analisarmos os dados do relatório em conjunto com os gráficos do Google Trends referentes à pesquisa do termo "chatbot" durante o período de 2016 a 2021, é possível atestar que a busca pelo tópico foi crescente durante o período e atualmente segue bastante oscilante quanto ao seu crescimento.
Assim, aproveitamos aquele momento da popularidade dos robozinhos para aprender um pouco mais a respeito de sua arquitetura e das tecnologias por trás do seu funcionamento, mas até então não tínhamos uma aplicação prática para tal. Por utilizarmos o mensageiro instantâneo Telegram desde a época em que nos conhecemos e nos aproximamos lá no segundo semestre da universidade, sabíamos que ele possuía capacidades interessantes a serem exploradas nesse sentido. O que não sabíamos era que tão cedo encontraríamos uma aplicação prática para elas.
Sempre fomos dois indivíduos bastante curiosos e, por conta disso, sempre tivemos muita facilidade de trabalhar em conjunto. Neste caso em específico, não foi diferente. Costumo brincar com o Matheus a respeito de termos perfis parecidos, tal qual como os Steve's tinham (Jobs e Wozniak, fundadores da Apple; um, rebelde revolucionário, o outro, engenheiro brilhante). Nossa atenção aos detalhes unidas com nossas habilidades que se complementam fazem com que nós, na minha humilde opinião, formemos uma ótima dupla, ainda que hoje cada um tenha trilhado o seu caminho de forma independente. Toda vez que surge a oportunidade de trabalharmos novamente em algo, seja em um projeto pessoal ou profissional, o resultado é sempre positivo.
O assunto naquela noite seguia outro rumo e voltava para o mesmo tema. Entretanto, em uma das minhas últimas reclamações acerca de uma funcionalidade em específico do sistema, uma ideia surgiu instantaneamente em uma de minhas falas e mudou o rumo de toda a nossa madrugada e, posteriormente, do nosso ano:
"E se a gente criasse uma forma de acessar o sistema por outro meio sem precisar de fato acessá-lo?"
A primeira versão
Aquele questionamento foi como uma explosão em nossas cabeças. Tínhamos atingido o Nirvana naquele momento. "Pronto, havíamos encontrado utilidade prática para os chatbots.", pensei comigo. Em cerca de 10 minutos, lá estava eu saindo da parede quente onde estava recostado em um rompante, pegando uma cadeira da cozinha daquelas de madeira bem rústicas e sentando ao lado do Matheus para iniciar uma longa e extensa pesquisa sobre como criar um chatbot para o Telegram. Naquele momento os trabalhos já estavam em segundo plano em nossas máquinas.
Sempre nos apoiamos durante esses momentos de loucura e, neste momento, não seria diferente. No histórico de pesquisas do Matheus (aquele que fica armazenado junto à conta de e-mail da Google) ainda consta o registro da nossa primeira busca, feita às 23h10. Lá estava ela: "python bot telegram". Simples e ingênua.
Iniciamos um brainstorm a respeito de como estruturaríamos toda aquela aplicação, que linguagem utilizaríamos para desenvolver o código que daria suporte para todo o seu funcionamento e quais seriam os desafios que enfrentaríamos para fazer aquela engenhoca toda que havíamos, até então, apenas projetado no papel, funcionar. No início, ficou acordado que desenvolveríamos o chatbot única e exclusivamente para uso próprio, sem haver divulgações a seu respeito. Fato esse que, felizmente, não se concretizou. Ficamos tão animados com os resultados que posteriormente o divulgamos.
Começamos nossa jornada estudando a API do Telegram, que é aberta e viabiliza a qualquer desenvolvedor recorrer à plataforma para desenvolver os robozinhos, desde que os mesmos obedeçam suas regras de segurança e privacidade. Iniciamos a madrugada estudando a respeito e estruturando tudo. Fizemos inúmeros rascunhos de como deveria funcionar a coisa toda, como seria o melhor processo, como obteríamos as informações etc. Nossos rascunhos foram evoluindo conforme as ideias iam surgindo em nossa discussão, e todos os insights foram fundamentais para estruturarmos logicamente a aplicação. Alguns foram descartados e outros se tornaram os principais diferenciais da solução que desenvolvemos.
Uma coisa era certa: precisaríamos utilizar uma técnica chamada scrapping sobre o código da página renderizado pelo navegador para obtermos as informações pertinentes, já que nativamente o sistema não tinha nenhuma outra forma de obtenção de dados. Scrapping nada mais é do que o processo de coleta e análise de dados brutos. Ou seja, é a possibilidade de, em uma página estática, obter a informação desejada de forma automática seguindo as diretrizes estabelecidas em um parser (o mecanismo de coleta). Sabíamos que o Python era de longe a melhor opção para tal atividade.
Sabíamos também que necessitaríamos reproduzir os procedimentos de autenticação necessários para a visualização dos dados contidos no sistema da universidade. Esse era um dos grandes desafios que havíamos de enfrentar. Embora tivéssemos experiências prévias trabalhando com protocolos do tipo HTTP/HTTPS, não havíamos de fato explorado algo que tivesse entrado em algum momento em produção. O mais perto que chegamos disso foi durante os trabalhos de uma disciplina de programação, onde comunicávamos por rede algumas placas Arduíno a uma aplicação desenvolvida em Java. Sim, em Java. Melhor ainda: Java com Swing. Assim, sabíamos que o Python mais uma vez era de longe uma das melhores opções para a tarefa.
O Python é uma linguagem de propósito geral, de alto nível, orientada a objetos e bastante funcional. Ela foi criada pelo holandês Guido Van Rossum, em 1991, e sua criação teve como inspiração enfatizar a importância do esforço do programador na escrita do código, priorizando a legibilidade sobre a velocidade ou expressividade. Ela é uma linguagem bastante objetiva e vem sendo amplamente utilizada pelos educadores como opção de ensino ao desenvolvedor que está tendo contato com a primeira linguagem de programação.
Por sua versatilidade, ela é empregada em uma variedade de ambientes, destacando-se por sua robustez e capacidade de realizar tarefas complexas, como processamentos de textos, dados científicos e aplicações em sistemas de Inteligência Artificial. Inicialmente, ela foi utilizada por nós na primeira versão do chatbot apenas como uma linguagem de script, mas logo sentimos a necessidade de expandir suas funcionalidades e ela se tornou não só a linguagem de script como também toda a base da programação desenvolvida nos meses seguintes.
Nosso calcanhar de Aquiles naquele momento, além do consumo dos dados e autenticação, era não ter a capacidade de receber notificações push toda vez que algo acontecia no sistema da universidade — uma nota era publicada, uma falta registrada etc. Antes do desenvolvimento do chatbot, passávamos horas atualizando a página do sistema de modo a ter a informação mais atualizada, e isso nos demandava tempo e atenção constantes. Após a programação do chatbot cinco dias após a ideia ter tomado forma, o problema das notificações push havia sido, em parte, sanado. Surgia assim o primeiro esboço lógico do chatbot, estruturado sob a perspectiva de prover notificações push sempre que um novo registro no sistema fosse feito.

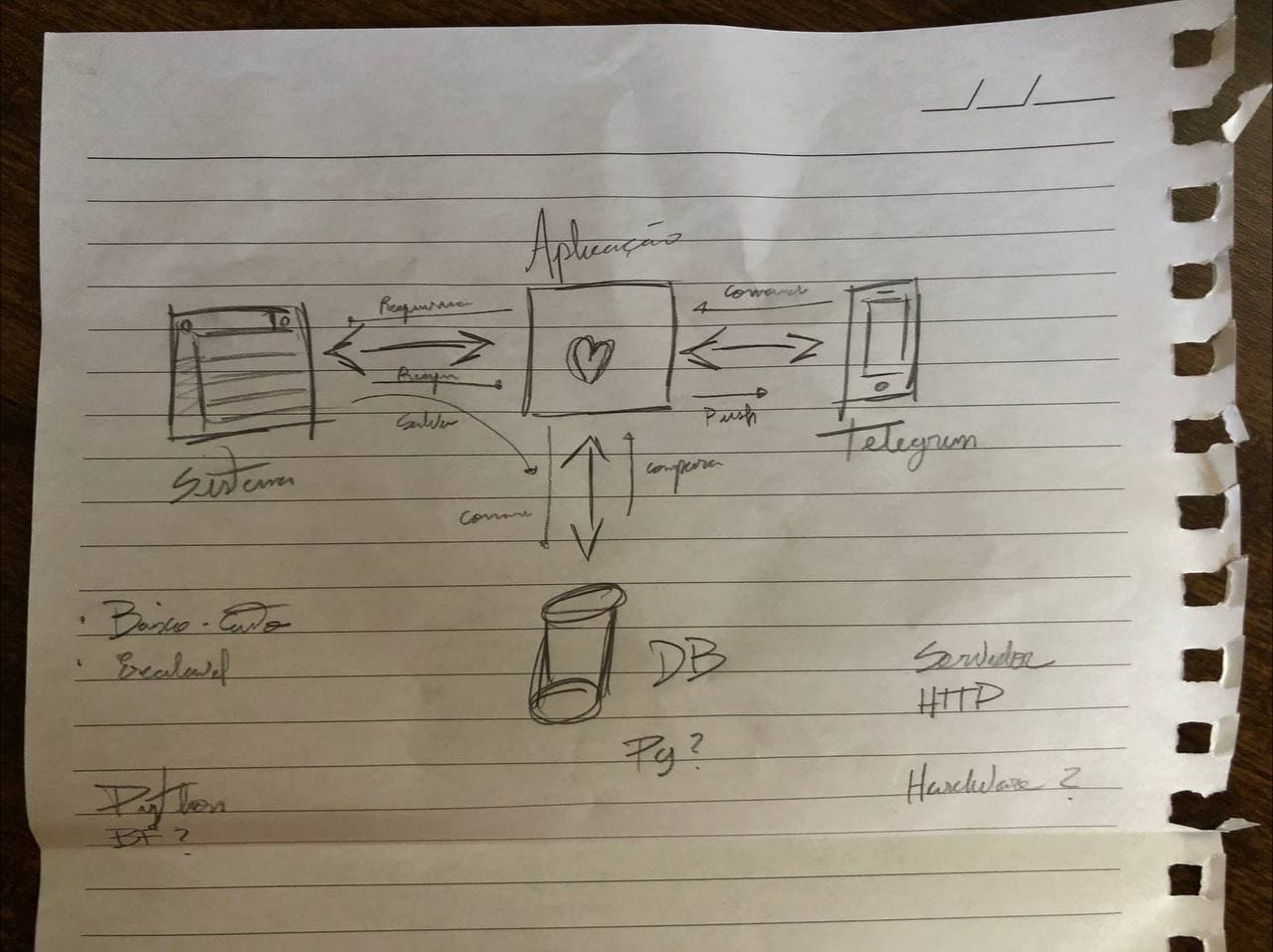
Esboço original da aplicação desenvolvida naquela fatídica noite.
Com base no esboço e na análise dos recursos contidos no sistema da instituição disponíveis ao aluno, definimos as primeiras funcionalidades que ofertaríamos com o serviço (até então exclusivo para nós). Em primeira instância, a ideia era de que fosse possível ter uma aplicação autônoma que fizesse toda a autenticação no sistema da universidade e extraísse os dados pertinentes com base no comando submetido ao chatbot. Todavia, para que tal problema fosse sanado, precisávamos arranjar uma forma de fazer a verificação dos dados em caso de alterações. Necessitaríamos, portanto, armazenar tais informações e recorrer a comparadores lógicos para verificar se houvera mudanças nas informações. Foi nesse instante que encontramos a necessidade de adicionar um banco de dados ao esquema.
A princípio, conversamos a respeito do modelo de banco de dados que deveríamos implementar e de cara chegamos a conclusão de que deveria ser um banco de dados estruturado. Optamos por utilizar o banco de dados PostgreSQL como base para todo o registro feito posteriormente. O banco de dados atuou como um middleware para a aplicação, ou seja, uma camada intermediária que fazia o armazenamento das informações e as disponibilizava em um lugar à parte para que tivéssemos a informação quase que imediata em nossas consultas.
O que fazíamos então era abstrair para o lado do aluno as consultas, proporcionando um serviço rápido e ágil, enquanto o parser fazia todo o trabalho custoso e repetitivo de acessar ao sistema inúmeras vezes ao dia e coletar as informações mais recentes. Essas informações eram comparadas com as que já existiam no banco de dados e, em caso de alterações, eram registradas e com base no registro de alteração eram disparadas as devidas notificações push aos usuários contendo tais informações. Foi dessa forma que abordamos a problemática das notificações, que se tornaram a principal funcionalidade do serviço que oferecíamos de forma gratuita (baseado no feedback que obtivemos dos alunos que usaram o serviço).
Além disso, estabelecemos algumas diretrizes para o desenvolvimento do chatbot. Elas se resumiam em três características simples, porém limitadoras, para que tivéssemos possibilidades de continuidade e crescimento futuro, dado que a ideia de abertura do serviço já permeava em nossos pensamentos naquele momento. Foram elas:
- A aplicação deveria fazer uso apenas de tecnologias open-source (de código-aberto) e/ou sem custos;
- A aplicação deveria ser capaz de ser executada em um hardware de pequeno porte (para que o custo de operação e manutenção não fosse elevado), visto que estaríamos ofertando o serviço de forma gratuita; e
- A aplicação deveria ter estabilidade e facilidade de uso, prezando sempre pela simplicidade.
Na madrugada em que passamos acordados pesquisando a respeito e entendendo como tudo funcionava, tínhamos como resultado do estudo e pesquisa pela manhã um código funcional realizando a autenticação no sistema e retornando as informações cruas, sem grandes formatações. Ele conseguia obter apenas as notas das disciplinas naquele momento, enquanto as demais funcionalidades estavam contidas no sistema apenas com uma mensagem indicando que não estavam habilitadas ainda.
Quando o aluno acessava o canal pelo mensageiro e disparava o comando referente à consulta das notas, o Telegram enviava uma requisição do tipo HTTPS para a nossa aplicação, que por sua vez executava o trecho de código relacionado àquela função e devolvia o resultado para o Telegram, tudo por uma conexão criptografada. Na execução do trecho específico, era feita a chamada da função interna que realizava a autenticação e então acessava as páginas referentes aos dados que estavam sendo solicitados e os extraía, devolvendo-os para que pudessem ser tratados e entregues na hora, de forma legível e estruturada ao aluno.
O código resultante daquela madrugada de estudos e a primeira versão funcional do chatbot é apresentado em sua totalidade abaixo.
import requests
import lxml.html
from bs4 import BeautifulSoup
from telegram import ParseMode
from telegram.ext import Updater, CommandHandler
class user:
users = []
def get_session(email, password):
session = ""
session = requests.session()
login_url = '<url de login do sistema da universidade>'
login = session.get('<url do sistema da universidade>')
login_html = lxml.html.fromstring(login.text)
hidden_inputs = login_html.xpath(r'//form//input[@type="hidden"]')
form = {x.attrib["name"]: x.attrib["value"] for x in hidden_inputs}
form['login'] = email
form['password'] = password
logado = session.post(login_url, data=form)
soup = BeautifulSoup(logado.content, 'html.parser')
for index in soup.find_all('script'):
if str(index.get_text().lstrip()).split("'")[1] == "Erro":
return session, False, str(index.get_text().lstrip()).split("'")[3]
else:
return session, True, "True"
def get_notas(usuario, senha):
session, logado, msg = get_session(usuario, senha)
url = "<url da home do sistema após autenticação>"
index = session.get(url)
url = "<url da página de avaliações>"
notas = session.get(url)
soup = BeautifulSoup(notas.content, 'html.parser')
count = 0
table = []
td = []
for index in soup.find(class_='tdatagrid_body').find_all('td'):
td.append(index.get_text().lstrip())
count += 1
if count == 6:
table.append(td)
td = []
count = 0
return table
def start(bot, update):
update.message.reply_text('Olá! Estamos finalizando as funcionalidades deste bot.')
def login(bot, update, args):
no_args = "Login inválido. Por favor, informe como parâmetros o seu usuário e a sua senha do sistema."
if len(args) != 2:
bot.send_message(chat_id=update.message.chat_id, text=no_args, parse_mode="Markdown")
return
s, logado, msg = get_session(args[0], args[1])
if logado:
u = []
u.append(update['message']['chat']['id'])
u.append(args[0])
u.append(args[1])
user.users.append(u)
update.message.reply_text('Pronto, fiz o login no sistema.')
else:
update.message.reply_text(msg + ".")
def atualizar(bot, update):
print(user.users)
update.message.reply_text('Esta função ainda não está habilitada.')
def deletar(bot, update):
update.message.reply_text('Esta função ainda não está habilitada.')
def notas(bot, update):
for u in user.users:
if update['message']['chat']['id'] == u[0]:
for i in get_notas(u[1], u[2]):
if float(i[5]) < 4:
media = "reprovado"
elif float(i[5]) >= 7:
media = "aprovado"
else:
if i[4] == "":
media = "em exame"
else:
if float(i[4]) >= 6:
media = "aprovado"
else:
media = "reprovado"
materia = ""
materias = str(i[0]).split(" ")
materias.pop(0)
materias.pop(0)
for o in materias:
if o == "I" or o == "II" or o == "III":
materia += o + " "
elif o == "A" or o == "DE" or o == "E":
materia += o.lower() + " "
else:
materia += o.capitalize() + " "
text = "<b>{}</b>\n<b>{}</b> na primeira avaliação\n<b>{}</b> na segunda avaliação\n<b>{}</b> de " \
"avaliação complementar\n<b>{}</b> de média final\nAté o momento, você está <b>{}" \
"</b>.".format(materia, verifica_vazio(i[1]), verifica_vazio(i[2]), verifica_vazio(i[4]),
verifica_vazio(i[5]), media)
bot.send_message(chat_id=update['message']['chat']['id'], text=text, parse_mode=ParseMode.HTML)
break
def verifica_vazio(v):
if not v:
return 0.0
else:
return v
def frequencia(bot, update):
update.message.reply_text('Esta função ainda não está habilitada.')
def horarios(bot, update):
bot.send_message(chat_id=update['message']['chat']['id'], text="t\nt", parse_mode=ParseMode.HTML)
update.message.reply_text('Esta função ainda não está habilitada.')
def cls(bot, update, args):
if args[0] == "<senha de administrador>":
user.users = []
update.message.reply_text('Lista apagada.')
else:
update.message.reply_text('Senha invalida.')
def main():
updater = Updater("<token obtido pelo telegram>")
dp = updater.dispatcher
dp.add_handler(CommandHandler("start", start))
dp.add_handler(CommandHandler("login", login, pass_args=True))
dp.add_handler(CommandHandler("atualizar", atualizar))
dp.add_handler(CommandHandler("deletar", deletar))
dp.add_handler(CommandHandler("notas", notas))
dp.add_handler(CommandHandler("frequencia", frequencia))
dp.add_handler(CommandHandler("horarios", horarios))
dp.add_handler(CommandHandler("cls", cls, pass_args=True))
updater.start_polling()
updater.idle()
if name == 'main':
main()
Na primeira versão do código, todo o armazenamento das informações sensíveis de autenticação era feito em um array. Se a execução da aplicação fosse interrompida, os dados eram perdidos e o usuário teria de realizar a autenticação novamente. Em versões de teste posteriores, fixamos as informações de autenticação naquele mesmo array que armazenava as informações para que não fosse necessária a autenticação toda vez que necessitássemos reiniciar a aplicação por algum motivo ou outro. Com a inserção do banco de dados em uma versão posterior o problema foi sanado.
Sabíamos que, a partir daquele momento, estávamos destinados a melhorar cada dia mais a aplicação até que a mesma atingisse nossos altos padrões de qualidade. O cansaço naquela manhã era enorme, mas a empolgação em desenvolver um projeto fora da sala de aula com chances de suprir todas as carências identificadas era tão grande que mal conseguíamos pregar o olho. Continuamos deitados trocando figurinhas durante mais uma hora a respeito do que podia ser feito e melhorado até cairmos no sono. Naquele dia, nascia toda a base da fundamentação do projeto que se tornaria o serviço oferecido aos alunos pelos próximos 11 meses.
A semana seguinte
Na semana seguinte, concentramos todos os nossos esforços em desenvolver as demais funcionalidades que não havíamos implementado naquela primeira madrugada de desenvolvimento do chatbot. Fizemos 4 commits no dia 21 de junho contendo o que não havíamos desenvolvido, dando prioridade àquelas funcionalidades de maior uso e importância para nós, como os registros de frequência e os horários de cada disciplina. Em cinco dias tínhamos a primeira versão da aplicação completa e operante, contendo os aspectos que já haviam sido definidos previamente.
Durante esses dias de desenvolvimento, fomos nos aprofundando também no estudo da API do Telegram e entendendo quais eram as possibilidades de evolução da aplicação para o futuro, ao mesmo tempo em que refatorávamos trechos do código para adquirir uma melhor organização e desempenho em sua execução. Até então, grande parte dos comandos estavam definidos em um único arquivo Python, que era responsável por lidar com todas as tarefas. Entretanto, sabíamos que aquela não era a melhor prática se quiséssemos manter seu desenvolvimento a longo prazo.
Com um Produto Mínimo Viável (MVP) em mãos, apresentamos a ideia para outro colega e amigo nosso, o Victor, e demonstramos seu funcionamento para avaliar seu feedback quanto a disponibilidade daquele serviço para a comunidade acadêmica da instituição. A empolgação dele frente ao que havíamos desenvolvido foi tanta que acabamos optando por liberar o acesso ao serviço para outros alunos. Embora as discussões entre nós já indicassem alguma propensão para a oferta do serviço, foi a empolgação de alguns amigos e indivíduos próximos aos quais nós demonstramos o projeto que fizeram com que batêssemos o martelo na nossa decisão. O fato se concretizou, porém, com o início do desenvolvimento da segunda versão estruturada, dez dias após a primeira versão estar pronta e operante, ainda que sem um servidor dedicado para tal.
Durante o período, fomos realizando também decisões estruturais em relação a como tudo ia funcionar. Por se tratar de um serviço oferecido por terceiros, deveríamos deixar claro ao aluno que aquele canal de comunicação era desenvolvido e mantido por dois outros alunos da instituição, que o projeto havia nascido até então apenas para uso próprio (e que estava em constante desenvolvimento para adaptar agora não só as nossas necessidades, mas também as de um coletivo), e que para o seu pleno funcionamento era necessário que armazenássemos seu nome de usuário e senha em nosso banco de dados, totalmente protegido do mundo externo e criptografado, para a autenticação e obtenção dos dados de forma automática pelo nosso parser. Assim, nasce um rascunho da primeira versão dos Termos de Uso a ser disponibilizado no chatbot quando um aluno fosse utilizar o serviço pela primeira vez.
Os Termos de Uso são necessários para descrever aos usuários quais são as regras que os mesmos devem respeitar ao usar um determinado produto e/ou serviço, e essas normas deverão corresponder como o produto e/ou serviço é ofertado. As informações contidas nos termos definem, em suma, todas as questões relacionadas à propriedade intelectual, jurídicas e de funcionamento. Eles funcionam como um contrato entre as partes e, naquele momento, ele foi escrito para dar conhecimento aos usuários do que estava acontecendo por baixo de toda aquela engenhoca, visando tornar nossa relação com os demais alunos em uma relação de plena confiança. Naquela época, entretanto, não havia nenhuma regulamentação quanto à proteção de dados como há hoje.
A Lei Geral de Proteção de Dados (LGPD), redigida durante o ano de 2018 e vigente desde setembro de 2020, define a obrigatoriedade de uma Política de Privacidade de Dados em caso de tratamento de dados pessoais no que se referem a coleta, produção, recepção, classificação, utilização, acesso, reprodução, transmissão, distribuição, processamento, arquivamento, armazenamento, eliminação, avaliação ou controle da informação, modificação, comunicação, transferência, difusão ou extração dos mesmos. Ou seja, enquanto um estabelece regras e diretrizes, o outro estabelece os direitos e deveres relacionados aos dados do usuário e como seus dados estão sendo usados e tratados.
Do ponto de vista jurídico, sabíamos que aqueles Termos de Uso de nada valiam. A elaboração dessa categoria de documento depende fortemente de conhecimentos não só jurídicos, mas também técnicos, e sua concepção sem o devido conhecimento implicava diretamente na inutilidade dos mesmos quando questionados judicialmente, já que o Código de Defesa do Consumidor considera o documento como um contrato de adesão e consequentemente anula cláusulas que possam parecer abusivas ao consumidor. Ademais, sabíamos também que os mesmos eram inválidos, pois o serviço era considerado por nós apenas como um estudo de caso, e não um produto comercial. O que fizemos foi apenas liberar o acesso a quem pudesse se interessar pelo serviço e, assim como nós, queria um pouco mais de praticidade em seu dia a dia. Tínhamos total conhecimento sobre todas as implicações acerca do desenvolvimento do projeto.
Além disso, outro fator agravante e também de senso comum é que a esmagadora maioria dos usuários não leem os Termos de Uso, apenas os aceitam e clicam em continuar para usar algum produto e/ou serviço de uma empresa. Atribui-se, muitas vezes, o fato deles serem extensos e complexos, cheios de jargões jurídicos. Fato se comprova com uma pesquisa da Universidade de York, em Toronto, em parceria com a Universidade de Connecticut divulgada em 2018, onde demonstra que 74% dos participantes de um estudo realizado a respeito do tema não leram os Termos de Uso de um determinado produto e 86% deles leram em menos de um minuto. Neste sentido, queríamos simplificar as coisas. Teríamos de ser bastante claros a respeito de como o serviço funcionava, então optamos por fazer uma versão compacta dos Termos de Uso e uma por extenso caso o mesmo tivesse interesse em lê-lo em sua completude.
Assim como tudo no chatbot, os Termos de Uso tiveram diversas atualizações e reformulações à medida que novas versões da aplicação eram desenvolvidas e postas no ar. A última versão simplificada dos Termos de Uso é exibida logo abaixo.
Olá!
Através deste canal, nosso propósito é fornecer a você uma fonte única e simples de acompanhar todas as suas informações armazenadas no [sistema da universidade], como avaliações, frequência, horários e muito mais, fazendo o uso de comandos, mensagens de áudio ou até perguntas simples como "Quais são as minhas notas?".
Vamos começar?
Leia com atenção nossos Termos de Uso e siga as instruções a seguir para finalizar a configuração inicial.
Termos de Uso
Pelo acesso e uso deste bot, você aceita e concorda em cumprir os termos legais de uso. Na utilização deste, você declara que leu e compreendeu estes termos e condições e concorda em ficar vinculado aos mesmos. A utilização dos serviços deste bot requer obrigatória e cumulativamente (i) a leitura e aceitação dos termos de uso e (ii) o cadastro e login em seu [sistema da universidade].
Nós, desenvolvedores deste canal, não compactuamos, incentivamos ou promovemos o uso ilegal dos seus dados. Nosso objetivo por meio deste é facilitar a sua vida automatizando tarefas do dia a dia. Não assumimos qualquer responsabilidade por aqueles que utilizam este canal para qualquer outra finalidade que não o monitoramento próprio do [sistema da universidade] da [universidade].
Caso você queira ler os termos de uso detalhados, utilize o comando /termos.
Essa versão sumarizava ao aluno que ele, ao utilizar o chatbot, declarava estar consciente e ter compreendido todas as suas limitações, concordava quanto a sua adesão e destacava que nós, os desenvolvedores e mantenedores daquele serviço, não compactuávamos com o uso ilegal dos dados e o uso do chatbot para qualquer outra finalidade que não o monitoramento do seu próprio perfil no sistema da instituição.
O aluno, ao acessar pela primeira vez a aplicação, poderia apenas realizar algum comando se aceitasse os Termos de Uso, independente de sua leitura. Essa responsabilidade estava na mão dos alunos que estavam ali querendo usar o serviço. Estruturamos a aplicação de modo que o aluno não pudesse realizar nenhuma tarefa importante enquanto não os aceitasse em sua totalidade. Assim, o único recurso que ficava disponível ao usuário antes dele aceitar os Termos de Uso era o contato conosco (os desenvolvedores do chatbot) para possíveis esclarecimentos.
A versão completa dos Termos de Uso é exibida em sua completude abaixo.
Termos de Uso
Geral
Todas as funcionalidades deste bot estão sujeitas aos termos e condições dos contratos aplicáveis que regem seu uso, que podem mudar de tempos em tempos. No caso de qualquer conflito, os termos fornecidos aqui prevalecerão. Os recursos e conteúdos fornecidos por este podem ser alterados a qualquer momento sem aviso prévio. Acredita-se que as informações fornecidas por este sejam confiáveis quando postadas, mas não há garantia de que elas sejam precisas, completas ou atuais em todos os momentos. Devido à natureza dinâmica da internet, os recursos que estão disponíveis no bot podem ser removidos a qualquer momento, e a localização dos itens pode mudar à medida que menus e funcionalidades são reorganizados. O usuário concorda expressamente que o uso deste bot é de sua total responsabilidade. Nenhum material pode ser modificado, editado ou retirado de contexto, de modo que seu uso crie uma declaração ou impressão falsa ou enganosa sobre as posições, declarações, informações ou ações.
Condições para Produtos e Serviços
Os termos e condições aplicáveis a qualquer produto, serviço ou informação serão aqueles determinados no momento da prestação do produto, serviço ou informação. Se você optar por acessar este bot, você o faz por iniciativa própria e é responsável pela conformidade com as leis locais, nacionais ou internacionais aplicáveis.
Confidencialidade
Trataremos todas as informações a seu respeito como confidenciais. Não divulgaremos qualquer informação que detenhamos sobre você, exceto nas seguintes circunstâncias: (i) sob obrigação de fazê-lo sob a lei brasileira e (ii) onde você forneceu sua autorização prévia por escrito para fazê-lo. Você não pode usar, exportar ou reexportar as informações ou qualquer cópia ou adaptação em violação de quaisquer leis ou regulamentos aplicáveis.
Garantia
Nós, desenvolvedores do bot, não fazemos quaisquer garantias, declarações, endossos ou condições, expressas ou implícitas, com relação ao bot ou as informações contidas nele, incluindo, sem limitação, garantias de comercialidade, operação, não infração, utilidade, integridade, precisão, atualidade, confiabilidade e adequação a uma finalidade específica. Além disso, não representamos ou garantimos que o bot estará disponível e atenderá aos seus requisitos, que o acesso será ininterrupto, que não haverá atrasos, falhas, erros, omissões ou perda de informações transmitidas, que nenhum vírus ou outra contaminação ou propriedades destrutivas serão transmitidas ou que nenhum dano ocorrerá no sistema do seu computador e/ou celular. Você é o único responsável pela proteção e backup adequados de dados e/ou equipamentos e por tomar precauções razoáveis e apropriadas para verificar se há vírus de computador ou outras propriedades destrutivas.
Copyright [universidade]
Todos os textos, imagens, gráficos, animações, vídeos, músicas, sons e outros materiais são protegidos por direitos autorais e outros direitos de propriedade intelectual pertencentes à [universidade], suas subsidiárias, afiliadas e licenciantes.
Este projeto não é oficialmente vinculado com a instituição de ensino [universidade].
Por favor, ajude-nos a melhorar. Caso haja alguma dúvida entre em contato utilizando o comando /desenvolvedores.
Assim que todos os aspectos referentes aos Termos de Uso foram definidos e a decisão de abrir o serviço a todos os membros da comunidade acadêmica foi feita, as discussões tomaram rumo para o armazenamento das informações e a oferta do serviço. Havíamos definido anteriormente o banco de dados utilizado pela aplicação, o PostgreSQL. Entretanto, ainda não havíamos decidido como nem por onde seria oferecido o serviço.
Pela limitação que tínhamos imposto durante nossas primeiras conversas quanto a conseguir executar a aplicação em um hardware de pequeno porte, cogitamos algumas opções, como uma máquina de 2007 que, vez ou outra, é usada por mim como servidor para alguma aplicação ou até mesmo a contratação de alguma VPS de baixo custo para suprir a nossa demanda. Todavia, não queríamos contratar um serviço visto havermos imposto a limitação de custo de operação baixo. Assim, chegamos a escolha do hardware que nos atendeu durante toda a oferta do serviço de maneira satisfatória: uma Raspberry Pi 2 (Model B).
A Raspberry Pi, também chamada de RPI, é uma placa de desenvolvimento de baixo custo extremamente compacta, do tamanho de um cartão de crédito, produzida pela Raspberry Pi Foundation, uma fundação inglesa sem fins lucrativos. Ela possui entradas USB para conexão de periféricos, como mouse e teclado, e pode ser utilizada inclusive como computador de mesa, se conectada a um monitor por meio da porta HDMI.
Ela foi escolhida por nós para esse projeto devido ao seu baixo custo, sua portabilidade e o seu baixo consumo de energia. Todo o seu hardware é integrado em uma única placa, e com ela pode-se fazer boa parte do que um computador de mesa faz, como navegar na Internet, reproduzir vídeos de alta definição, criar planilhas e processar textos, além de servir como servidor dependendo do tipo da aplicação.

Raspberry Pi 2 (Model B) ao centro da imagem: o hardware utilizado como servidor, hospedando e gerenciando todo o serviço ofertado durante cerca de 1 ano.
A sua versão mais recente, Raspberry Pi 4 (Model B), utiliza um SoC com arquitetura ARM de quatro núcleos operando na frequência de 1,5 GHz, memórias RAM LPDDR4 que variam de 2 GB a 8 GB, possuem 4 portas USB, sendo duas delas USB 2.0 e duas USB 3.0, além de porta de alimentação USB-C, porta Gigabit Ethernet, duas portas micro-HDMI, entrada de 3,5 mm para áudio composto e uma GPIO de 40 pinos com suporte a interfaces I2C, SPI e UART.
Como conectividade sem fio, a placa possui Wi-Fi 802.11ac dual-band e Bluetooth 5.0 integrados. Seu armazenamento é todo feito por um cartão MicroSD, dado que a RPI não inclui uma memória não volátil integrada, como um disco rígido, por exemplo. O cartão MicroSD é responsável por armazenar não só o Sistema Operacional (baseado em kernel Linux) mas também os dados do usuário.
A versão da placa que tínhamos em mãos era a Raspberry Pi 2 (Model B), lançada em 2015. Diferente da versão mais recente da RPI, a segunda versão da placa tem como configurações um SoC de arquitetura ARM de quatro núcleos operando a 900 MHz, memória RAM de 1 GB, conexão Ethernet do tipo Megabit, possui 4 portas USB 2.0, uma porta Micro-USB para alimentação, uma porta HDMI e uma saída de áudio de 3,5 mm, bem como a entrada para o cartão MicroSD.
Em relação às versões posteriores da RPI, a edição que tínhamos à disposição da placa não possuía nenhuma conexão sem fio integrada. Neste caso, foi necessário um adaptador Wi-Fi USB para possibilitar seu funcionamento sem a necessidade do hardware permanecer conectado ao roteador por um cabo de rede.
Feita a escolha do dispositivo que nos atenderia como servidor para a aplicação, direcionamos nossos esforços em tempo integral para o desenvolvimento de todos os aspectos do chatbot, fazendo constantes melhorias para a obtenção de um desempenho satisfatório do serviço considerando as limitações de hardware do dispositivo. Discutíamos naquele momento desde como os dados eram apresentados para os alunos no mensageiro até como uma informação era requisitada, formatada e salva em nosso banco de dados.
A primeira versão funcional tinha 808 linhas de código divididas entre quatro arquivos diferentes que lidavam com diferentes demandas e cobriam a maioria dos recursos oferecidos pelo sistema da universidade ao aluno. Além disso, integramos algumas funcionalidades específicas para nós, administradores do serviço, para que fosse possível a conferência de estatísticas de uso do serviço e do servidor onde ele estava hospedado.
Quando optamos por oferecer o serviço a toda a comunidade acadêmica, fomos obrigados a reestruturar toda a aplicação para que a mesma pudesse ser escalonada e mantida a longo prazo. Nascia assim o projeto arquitetural da segunda versão que iria ao ar no início do próximo semestre e que atenderia a demanda de alunos crescente daquele período.
A segunda versão
No dia 1 de julho de 2018, data referente ao primeiro commit da segunda versão do chatbot, já havíamos decidido ofertar o serviço a todos os membros da comunidade acadêmica e adicionar novos recursos a ele, de forma a cobrir todas as funcionalidades contidas no sistema da universidade, exceto aquelas em que eram necessárias confirmações de dados por parte dos usuários. Em outras palavras, apenas realizávamos a coleta destes mesmos dados. A escrita deles era realizada somente em nosso banco de dados e em ocasiões bastante específicas, impossibilitando o aluno de, por exemplo, realizar sua rematrícula pelo chatbot.
Identificamos a necessidade de algumas funcionalidades que eram abertas ao público e não precisavam necessariamente de autenticação para a consulta dos dados. Um exemplo disso é a captura de editais no portal da universidade, abertos ao público. Esses recursos foram adicionados de modo a unir todos os recursos mais utilizados pelos alunos em um único canal onde ele pudesse realizar a esmagadora maioria de suas consultas durante o semestre, e ainda tivesse como funcionalidade principal as notificações push caso novas informações ou alterações das informações vigentes fossem detectadas.
Na nova versão, iniciamos a discussão pelas funcionalidades de administradores do chatbot, dado que queríamos ter a possibilidade de extrair informações, elaborar estatísticas e controlar aspectos referentes ao servidor diretamente pelo mesmo canal, sem que fosse necessário o acesso físico ao servidor para a conferência ou manejo das informações. O menu de administradores, disponibilizado aos usuários com base no identificador único de usuário dentro de cada escopo, continha os comandos de:
- Listar todos os usuários cadastrados no sistema (possibilitando a conferência de informações sobre cada usuário, como identificador único, nome e curso);
- Alertar um usuário em específico com base no seu identificador único;
- Enviar um comunicado a todos os usuários;
- Listar todas as sugestões recebidas pelos alunos da instituição para que pudéssemos melhorar ainda mais o serviço ofertado (ocasionando em uma troca mútua);
- Listar estatísticas de uso do hardware onde o serviço estava sendo executado;
- Exibir o log de coleta de informações do parser;
- Reiniciar o servidor; e
- Atualizá-lo com base nas atualizações mais recentes feitas no repositório do GitHub do projeto.
Com esses comandos definidos, podíamos fazer a gerência de todos os artefatos, fossem eles usuários ou o próprio hardware. Entretanto, novas necessidades foram surgindo ao decorrer do desenvolvimento, o Telegram passou a disponibilizar novos recursos dentro dos chatbots e consequentemente fomos explorando todas as possibilidades. Assim, adicionamos à lista ainda os recursos de:
- Criar uma enquete e enviar a todos os usuários;
- Conferir os resultados das enquetes;
- Listar estatísticas de uso das funcionalidades em geral ou de um usuário em específico; e
- Exibir a lista de erros de requisição de informações e/ou de rede.
Em relação ao aluno, era possível executar pelo chatbot cerca de 97% das funcionalidades contidas no sistema da instituição. A lista com todos os comandos disponíveis é exibida em sua totalidade abaixo.
- Realizar o login no sistema da universidade (vinculando o seu identificador único com as credenciais de acesso do sistema);
- Realizar a exclusão de seus dados em caso de desistência de uso do serviço;
- Fazer uma sugestão para que pudéssemos melhorar ou adicionar novas funcionalidades;
- Configurar a frequência de notificações push;
- Exibir as notas por disciplina registradas no sistema;
- Exibir a frequência por disciplina registradas no sistema;
- Exibir os horários por disciplina registradas no sistema;
- Exibir a lista de disciplinas em curso registradas no sistema;
- Exibir as datas das provas por disciplina registradas no sistema;
- Exibir o histórico com todas as informações referentes ao curso;
- Exibir o currículo completo do curso;
- Solicitar um atestado de matrícula;
- Solicitar o boleto para pagamento da mensalidade;
- Exibir os últimos editais publicados no portal da instituição;
- Exibir o número da chave de matrícula;
- Exibir os últimos e-mails recebidos no sistema da instituição;
- Solicitar o link de acesso do ambiente virtual da instituição (moodle);
- Solicitar o link de acesso para o portal minha biblioteca;
- Exibir os créditos pelo serviço;
- Exibir os termos de uso do chatbot;
- Solicitar ajuda; e
- Exibir o menu de comandos contendo todas as informações organizadas conforme a frequência de uso de cada aluno.
Com base nos comandos definidos, estabelecemos rotinas lógicas para cada funcionalidade, e as limitamos com base na aceitação dos Termos de Uso e no vínculo das informações. Ao acessar pela primeira vez o serviço, o aluno se deparava com os Termos de Uso seguido de opções para aceitá-los ou recusá-los. Caso o aluno optasse por recusá-los, não era possível realizar nenhum comando que necessitasse acesso ao sistema da instituição. Se, por outro lado, o aluno optasse por aceitar os Termos, o fluxo lógico seguia e a próxima função executada pedia para que o usuário informasse suas credenciais de acesso ao sistema para que fossem vinculadas ao seu identificador único e fosse feito o registro junto ao nosso banco de dados para que o parser pudesse realizar o login no sistema de forma automática e coletar as informações pertinentes.
Em primeira instância, as credenciais eram enviadas como parâmetros por meio do disparo de um comando. Todavia, conforme fomos evoluindo a aplicação, o processo passou a ser dinâmico, como em uma conversa mesmo. O chatbot executava uma rotina que primeiramente solicitava o nome de usuário e então, após o aluno ter informado tal informação, a senha. Caso o usuário errasse a senha no fluxo, uma mensagem de erro era exibida e a rotina permanecia em loop até que a senha correta fosse informada e o chatbot recebesse a mensagem de sucesso na autenticação com o sistema.
Assim que o vínculo era feito, o chatbot informava ao aluno que o Login havia sido feito com sucesso e exibia logo em seguida o menu contendo todas as funcionalidades disponíveis para que o aluno pudesse interagir diretamente com ele, ao toque de uma tela. A partir daí, ele estava livre para executar qualquer função e conferir suas informações, e estava apto a receber notificações push no instante em que novas informações fossem coletadas pelo parser.

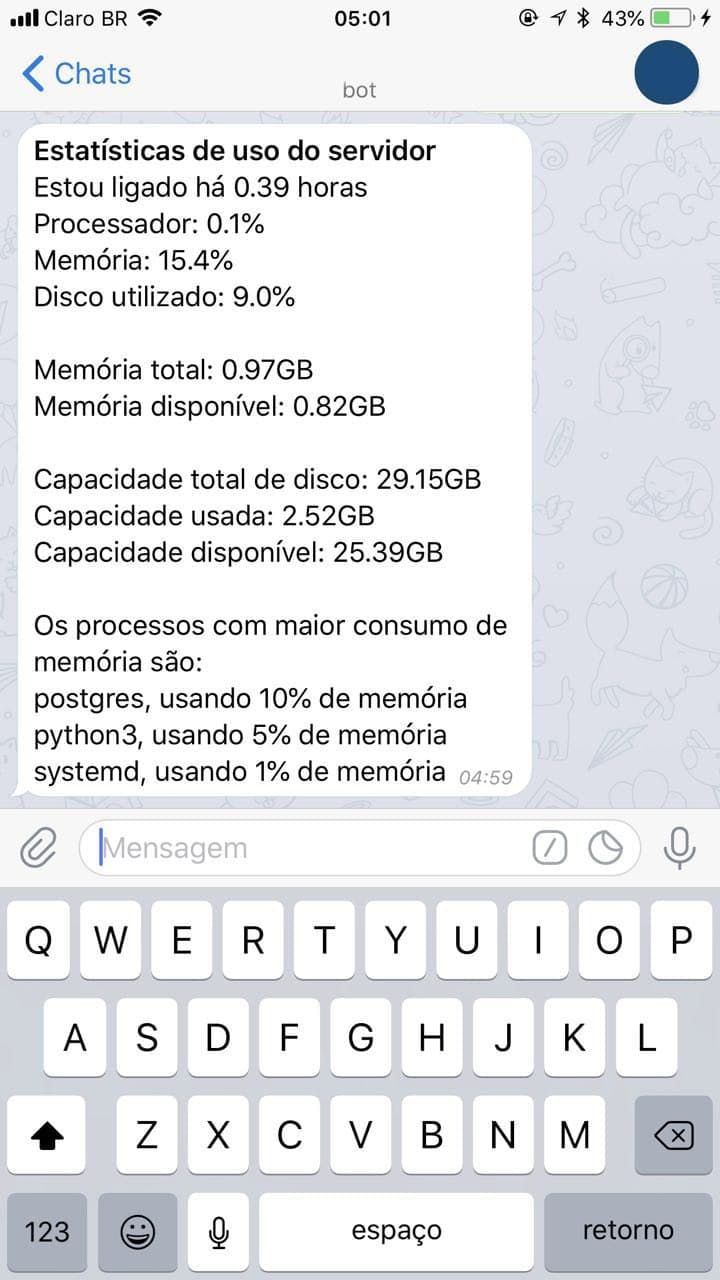
Estatísticas de uso do servidor disponíveis aos administradores.
Quando abrimos o serviço aos alunos da instituição, obtivemos um crescimento orgânico bem grande. Um amigo mostrava para o outro, que mostrava para outro, que mostrava para a namorada, e assim foi. Conforme o número de usuários ia crescendo, maior era a nossa responsabilidade para com a oferta do serviço e a proteção dos dados, que estavam sob nossa responsabilidade, e maior se tornou a nossa visibilidade entre os gestores da instituição e o corpo docente.
O tempo foi passando, novos usuários foram aderindo ao serviço, feedbacks bastante positivos foram surgindo e o desenvolvimento foi avançando conforme necessidade. Todavia, ainda havia um problema que precisávamos sanar: o envio de mensagens contextuais.
Em um chatbot, o contexto da informação é importantíssimo para que ele possa saber qual rumo tomar, assim como em um diálogo. Por definição, diálogo é a fala onde há a interação entre dois ou mais indivíduos. Ou seja, é uma troca lógica entre dois indivíduos para manifestar suas ideias ou troca de impressões em busca de um entendimento. Nós, seres humanos, possuímos tal característica de forma inata desde a revolução cognitiva ocorrida entre 70 e 30 mil anos atrás, a chamada narrativa oral. Ela possibilitava aos homo sapiens contarem histórias ao redor de fogueiras, acreditar em habilidades de narrativas abstratas e na invenção de coisas imateriais (ou seja, não palpáveis).
Assim como a leitura, a fala é uma habilidade que precisa-se conquistar. Na narrativa escrita, surgida há cerca de 6 mil anos, muda-se esse paradigma. Nossa neuroplasticidade, ou seja, nossa habilidade de ler e se comunicar, é intercambiada com o tempo. Assim, a comunicação passa a se assemelhar mais com a nossa capacidade de entender e manipular números (uma invenção cultural) e, a partir dos grandes berços da escrita, nossos cérebros precisam transformar símbolos em ideias, sons e ações. Nossa comunicação se passa a valer então de um sistema simbólico capaz de traduzir tudo aquilo que uma língua ou uma cultura possuem.
Nessa perspectiva, o contexto age como um fator norteador dentro de uma conversa, e pode ser tanto uma data, horário e o local de uma conversa quanto informações dinâmicas definidas durante a conversação e que podem ser alteradas a todo momento. Os seres humanos são complexos e conversas naturais são ainda mais. Assim, variam de acordo com a relação entre os indivíduos. O grande desafio é, portanto, encontrar uma forma de processar logicamente esses contextos computacionalmente. Quanto mais sensível ao contexto o chatbot for, maior será a chance da conversa ser produtiva e maior será a satisfação do receptor da mensagem.
Assim, na tentativa de solucionar o problema contextual encontrado, adicionamos a integração do chatbot com dois serviços externos: o DialogFlow, da Google, e o Azure Speech to Text, da Microsoft. O primeiro deles é uma plataforma de compreensão de linguagem natural usada para projetar e integrar interfaces de usuário conversacionais em aplicativos móveis, web, dispositivos, bots, sistemas de resposta de voz e dispositivos relacionados. O segundo é responsável por converter a voz natural em texto, transcrevendo o que foi dito em uma mensagem de áudio em texto para que ele possa ser tratado por um serviço como o DialogFlow, por exemplo.
Em nosso fluxo, toda vez que um usuário enviava uma mensagem de texto para o chatbot, ele encaminhava as mensagens recebidas para o motor contextual do DialogFlow que, por sua vez, tomava as devidas decisões baseadas nas regras estabelecidas no treinamento do modelo matemático e retornava uma resposta ao chatbot. Conforme mais pessoas iam interagindo com ele de diferentes maneiras, melhor era a acurácia na resposta. Todas as mensagens sem um contexto ou que não estivessem no escopo da aplicação eram descartadas pessoalmente por mim.
Além da integração com o DialogFlow, foi feita a integração com a Azure. O usuário enviava uma mensagem de áudio, que era salva momentaneamente e encaminhada para a nuvem da Microsoft para processamento. O resultado deste processamento era enviado para a nuvem da Google para que entrasse no motor contextual e a resposta oriunda era repassada de volta para o chatbot, que retornava sempre alguma informação, fosse ela a solicitada, fosse ela uma mensagem genérica sobre não ter entendido o contexto da informação. Após o final do ciclo, a mensagem de áudio era apagada e nenhum registro que permitisse a identificação do usuário era armazenado.
As mensagens, tanto de texto quanto de áudio, eram tratadas anonimamente na plataforma da Google. As únicas informações armazenadas em relação à integração com ambos os serviços era a quantidade de vezes que eles foram executados pelos usuários em geral e por usuários específicos, entretanto, não era possível identificar qual mensagem era de qual usuário.
No decorrer do desenvolvimento da segunda versão, enviamos um total de 317 commits para o repositório no GitHub contendo pouco mais de 14 mil linhas de código ao todo. Tivemos um crescimento de 1748% em relação à primeira versão do chatbot. Nosso último commit, feito no dia 14 de abril de 2019, teve como cabeçalho o singelo título de fim e marcava a data de encerramento do serviço. Era hora de avançar.
Fim das atividades
No decorrer dos mais de 11 meses em que estivemos ativamente envolvidos com o projeto e o seu desenvolvimento, tivemos inúmeras oportunidades de crescimento, tanto pessoal quanto profissional. Nos tornamos melhores profissionais, aprendemos a lidar melhor com algumas situações que foram surgindo no decorrer do caminho, melhoramos nossa lógica de programação e impactamos a vida de cerca de 450 alunos que aderiram e usaram o serviço durante o tempo em que ele foi ofertado gratuitamente a todos.
Infelizmente, toda história tem um fim. Por motivos de força maior, optamos por finalizar a oferta do serviço, visto que o mesmo estava demandando mais do que podíamos ceder naquele momento, dando oportunidade para que novos projetos surgissem e novos interesses fossem descobertos. Deixamos com o chatbot um legado que perdurou (e ainda perdura) entre os inúmeros indivíduos que tivemos contato durante o desenvolvimento, além de alunos que usavam o serviço e deixavam comentários sobre o quão simples ele era e tantas outras inúmeras informações que vão surgindo toda vez que o assunto é revisitado.
Tivemos muitos momentos de alegria desenvolvendo a aplicação, uma atenção enorme aos detalhes de cada fluxo lógico e de conversações, e ainda mais atenção quanto à disponibilidade do serviço. Ele esteve operante durante 99,8% do tempo em que foi ofertado, e as poucas vezes em que saiu do ar ou foi para manutenção ou foi por motivos de causas naturais (falta de energia elétrica, interrupção do sinal de internet etc).
O aprendizado maior que deixamos com a experiência adquirida durante esse projeto é o de sempre correr atrás daquilo que você julga ser o ideal naquele momento, não deixar a ideia ou o tempo escapar pelas suas mãos. Se não fosse por aquela fatídica noite, sabe-se lá quais outros caminhos teríamos seguido. E nem queremos saber. O que importa é que confiamos em nosso potencial, nos comprometemos com aquilo que acreditávamos e materializamos uma ideia que nasceu de uma frustração com um sistema bastante chinfrim em um serviço elogiado por mais de 95% de seus usuários.
Se não fosse pela frustração, pelo descontentamento e por aquele singelo questionamento em uma noite amena e tranquila de inverno, talvez não tivéssemos toda a experiência, a maturidade e o reconhecimento que temos hoje. Honramos com a nossa missão desde o momento em que mergulhamos de cabeça no projeto e saímos dele de cabeça erguida e ainda mais fortes, com um estudo de caso bastante positivo e ótimas lembranças e histórias para contar.
Bônus
Curiosidades que fazem parte do projeto e que, direta ou indiretamente, não tiveram menções honrosas na publicação. Todavia, não é porque não foram incluídas que deixam de ter sua importância. São elas:
- Tivemos reconhecimento do Excelentíssimo Senhor Reitor da instituição pelo serviço ofertado, por toda a ética e proatividade para com o desenvolvimento do projeto;
- Deixamos muitos usuários órfãos com a notícia da suspensão do serviço (recebemos MUITOS e-mails a respeito);
- O servidor passou diversos meses colado com uma fita isolante ao lado do meu guarda-roupas por ser perto da única tomada disponível para ele no meu quarto;
- Um dia eu cheguei em casa e o servidor tinha caído (literalmente) de onde ele estava;
- Às vezes íamos enviar uma mensagem um para o outro durante o desenvolvimento e acabávamos falando sozinhos com o bot;
- Uma pessoa de cargo importante na instituição durante aquele período certa vez comentou em uma publicação referente ao serviço: “Nossos alunos aprendem e fazem, aprendem fazendo e, em fazendo, aprendem! Não fosse isso suficiente, servem, contribuem, auxiliam, empreendem e crescem!”;
- Na segmentação de postagens que realizamos nas redes sociais, encontramos alunos falando positivamente no Twitter e no Facebook a respeito do serviço;
- Deixamos alguns egos feridos no caminho pelo sucesso do projeto; e
- Faríamos tudo novamente.
Agradecimentos
Deixo um agradecimento especial ao Matheus por me ajudar a organizar os fatos em ordem cronológica durante o período de estruturação desta publicação. Se não fosse pelo nosso longo histórico de conversas mantido no Telegram durante todos esses anos de sólida amizade e por todo o apoio para com o outro, não teríamos o registro de metade das informações aqui contidas. Obrigado!
Deixo um agradecimento especial também a todas as pessoas que, direta ou indiretamente, contribuíram para que o projeto tomasse forma e atingisse a proporção que atingiu, seja dando sugestões ou ajudando a promover o serviço devido a sua qualidade e/ou recursos. Somos realmente gratos por tudo isso.